อยู่ในระหว่างการปรับปรุงเนื้อหา

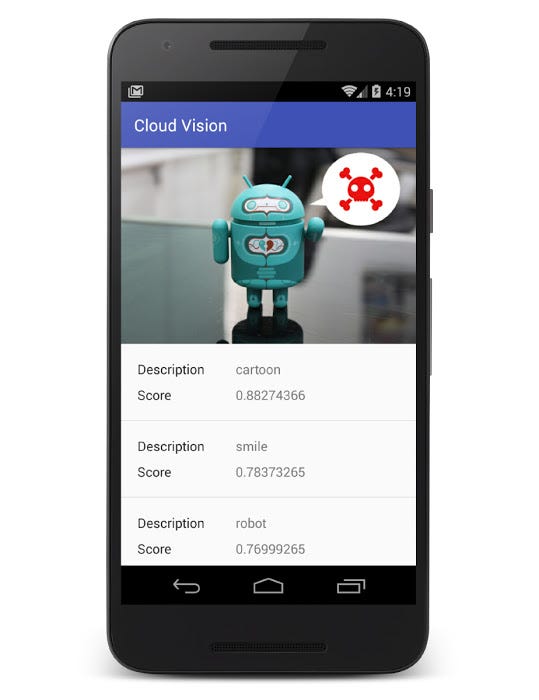
เมื่อไม่นานมานี้ทาง Google ได้เปิดบริการตัวใหม่ที่ชื่อว่า Cloud Vision API ซึ่งเป็นบริการที่จะช่วยให้นักพัฒนาสามารถวิเคราะห์ภาพที่ต้องการได้
เย้ ในที่สุดก็มีวันนี้แล้ว เพราะเจ้าของบล็อกเชื่อว่ามีนักพัฒนาหลายๆคนที่ใฝ่ฝันอยากทำแอพหรือโปรแกรมที่วิเคราะห์ภาพถ่ายได้ เช่น มีอะไรอยู่ในภาพ เป็นภาพแบบไหน หรือแม้แต่การทำ OCR เป็นต้น ซึ่งเรื่องพวกนี้เป็นเรื่องยากมากที่จะมานั่งทำเอง
ซึ่งเจ้าของบล็อกก็ไม่รอช้า ไปนั่งลองเล่นคร่าวๆดูว่ามันทำอะไรได้บ้าง ใช้งานยังไงบ้าง ก็เลยมาเล่าสู่กันฟังครับ
รู้จักกับ Cloud Vision API กันก่อน
Cloud Vision เป็นหนึ่งในบริการของ Google Cloud Platform ที่ใช้ความสามารถจากเทคโนโลยีของ Google เพื่อช่วยอำนวยความสะดวกในเรื่องการวิเคราะห์ภาพ ซึ่ง API ตัวนี้จะช่วยสามารถเข้าใจได้ว่าเนื้อหาของภาพนั้นคืออะไร

โดยใช้ความสามารถของ Machine Learning ที่ทาง Google ทำมาพักใหญ่แล้ว ดังนั้นจึงรับประกันได้ว่าความสามารถของ API ตัวนี้ไม่ธรรมดาๆแน่ๆ เพราะข้อมูลหลังบ้านที่ใช้ในการวิเคราะห์นั้นมีเยอะมาก และใช้เทคโนโลยีตัวเดียวกันกับที่ใช้ใน Google Photos ด้วย
เพราะในความเป็นจริงนั้นการวิเคราะห์ภาพใดๆก็ตามต้องบอกเลยว่าด้วยพลังของมือถือหรือคอมพิวเตอร์หนึ่งเครื่องในตอนนี้ก็คงไม่เพียงพอ เพราะต้องมีอัลกอริทึมมากมายเพื่อใช้ในการวิเคราะห์ รวมไปถึงข้อมูลใหม่ๆจากหลายๆที่ที่ต้องนำมาใช้ด้วย ดังนั้นวิธีที่ดีและแม่นยำที่สุดก็คงไม่พ้นการอัพโหลดภาพขึ้นเซิฟเวอร์แล้วให้เซิฟเวอร์ทำการวิเคราะห์ภาพจนเสร็จแล้วส่งผลลัพธ์ที่ได้กลับมา นี่แหละวิธีการใช้ Cloud Vision API อย่างคร่าวๆ
ซึ่ง Cloud Vision API สามารถวิเคราะห์ได้ทั้ง
* ใบหน้าของคน
* ประเภทของวัตถุ
* โลโก้
* ข้อความ
* สถานที่สำคัญ
* ภาพที่ไม่เหมาะสม
แถมทั้งหมดนี้สามารถวิเคราะห์ได้พร้อมๆกันในทีเดียวเลยนะเออ และที่ชอบอีกอย่างก็คือถ้าผู้ที่หลงเข้ามาอ่านคนไหนใช้บริการ Google Cloud Storage ก็สามารถส่งภาพจากในนั้นเข้า Cloud Vision API ได้โดยตรงเลยนะ (กำหนดได้)
เตรียมให้พร้อมก่อนจะเริ่มใช้งาน
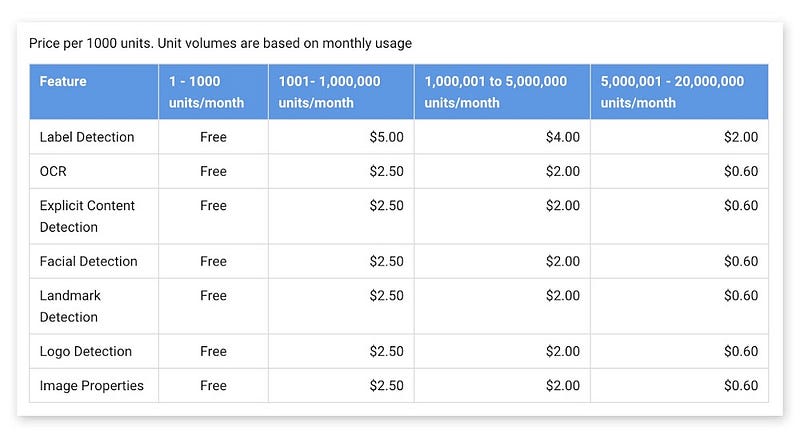
ตอนนี้ Cloud Vision อยู่ใช้ช่วงพึ่งเริ่ม และสามารถทดลองใช้งานได้ฟรี 2 เดือน สามารถทดลองใช้งานจากหน้าเว็ปของ Cloud Vision ได้เลย Google Cloud Vision API
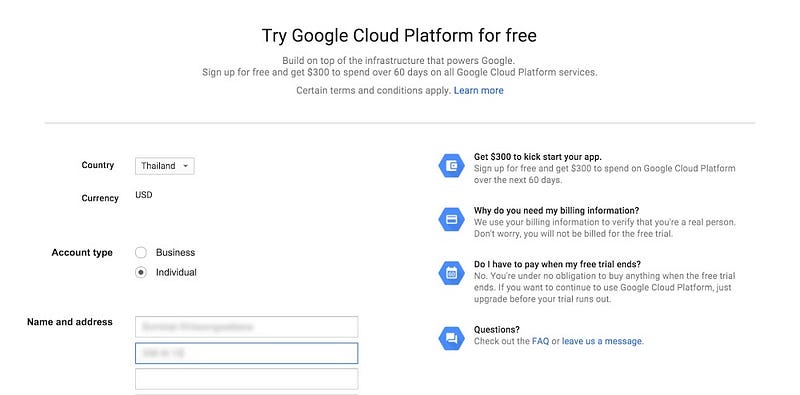
ซึ่งจะต้องสมัคร Google Cloud Platform เสียก่อน โดยในขั้นตอนนี้จะบังคับให้กรอกบัตรเครดิตลงไป จากนั้นบัตรก็จะโดนหักเงินนิดหน่อยเพื่อทดสอบ (เดี๋ยวคืนให้ทีหลัง)
สำหรับการสมัครใช้งาน Google Cloud Platform ครั้งแรกจะทดลองใช้ได้ฟรี 60 วัน และมีเครดิตให้ $300

จากนั้นจะเข้าสู่หน้า Google Developer Console ทันที สร้างโปรเจคขึ้นมาซะ ตั้งชื่ออะไรก็ได้
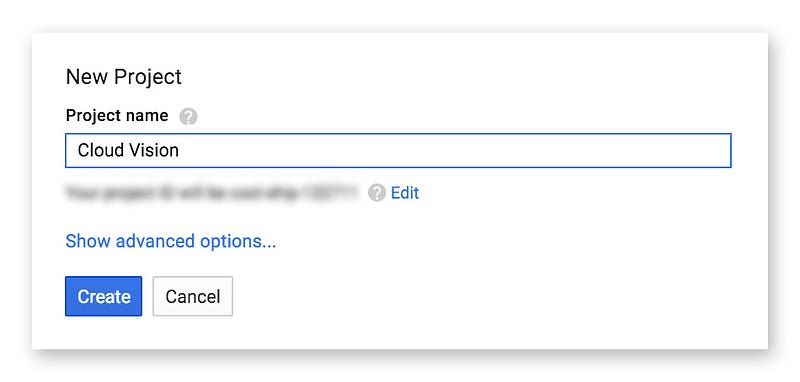
หลังจากสร้างโปรเจคแล้ว ต้องไปเปิดใช้งาน Cloud Vision API ก่อนนะ ไม่งั้นจะใช้งานไม่ได้ ซึ่งที่หน้าหลักโปรเจคจะเห็นว่ามีอะไรแสดงอยู่เยอะแยะไปหมด ให้ลองมองหา Use Google APIs ให้ดีๆ แล้วกดเลือก Enable and manager APIs
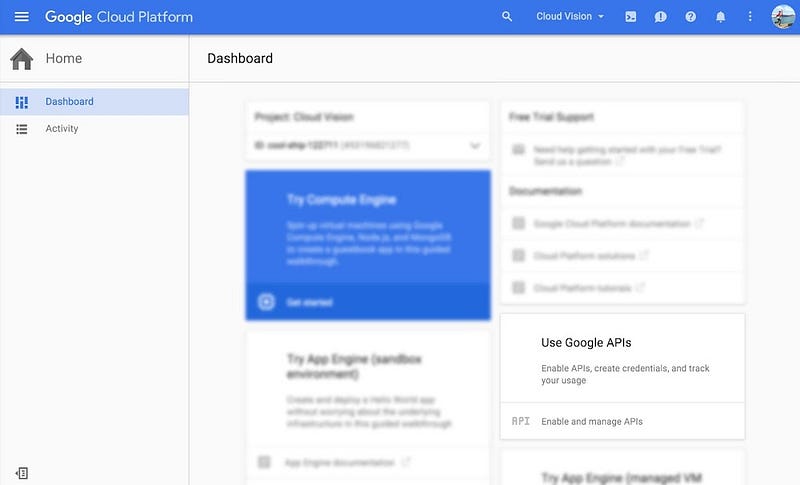
ที่หน้าต่างนี้จะต้องเลือก API ที่ต้องการใช้งาน ดังนั้นให้มองหา Cloud Vision API ซะ แนะนำว่าให้พิมพ์ค้นหาในช่องค้นหาเลย เดี๋ยวก็โผล่ขึ้นมาให้เลือกเองแหละ
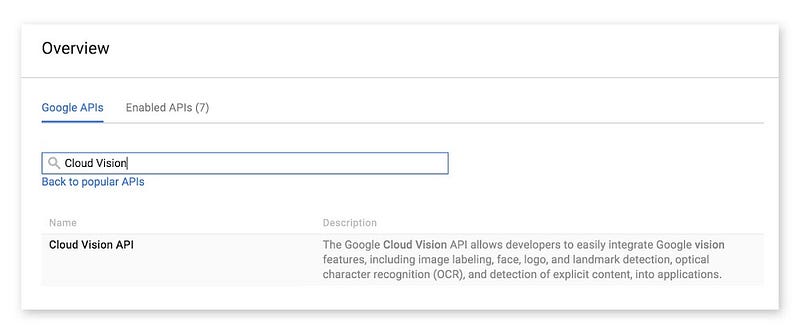
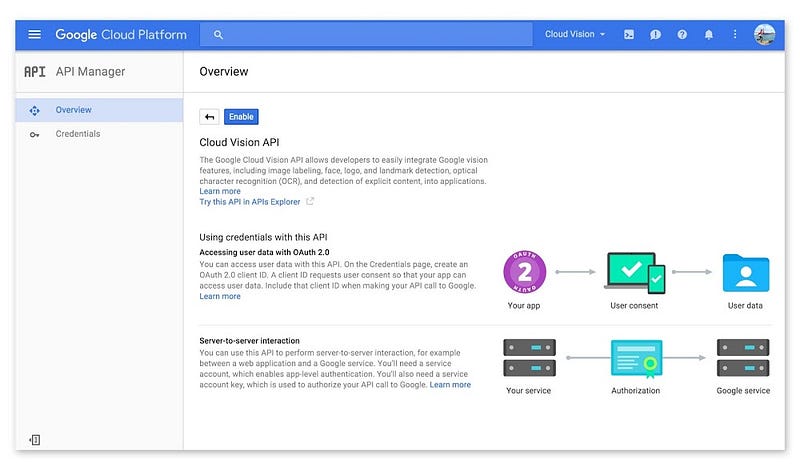
เมื่อเปิดใช้งานแล้ว จะมีการแจ้งว่าให้เพิ่มและสร้าง Credential ก่อน ถึงจะใช้งานได้ (ก็สร้างซะ)
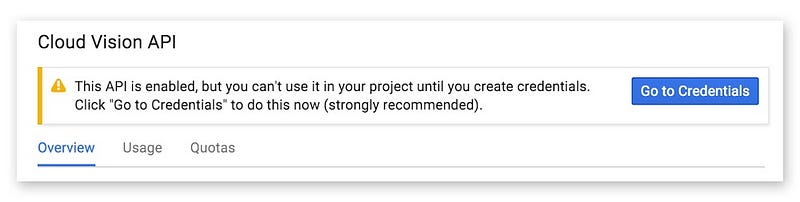
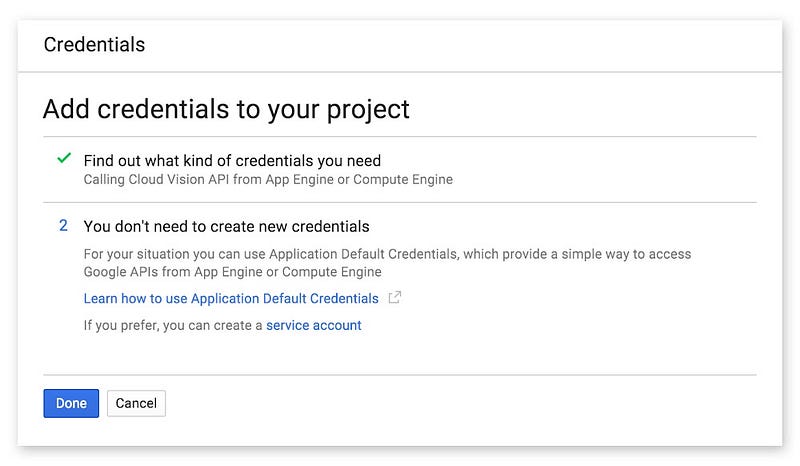
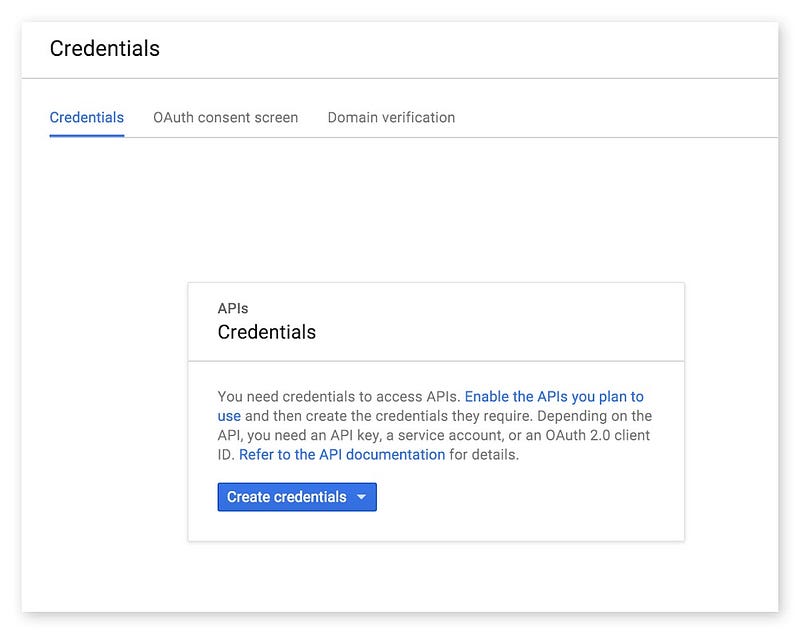
ในขั้นตอนการสร้าง Credential สำหรับ Cloud Vision API สามารถสร้างเป็น API Key หรือ OAuth Client ID ก็ได้ โดยในบทความนี้เจ้าของบล็อกยกตัวอย่างเป็นการใช้ API Key นะครับ
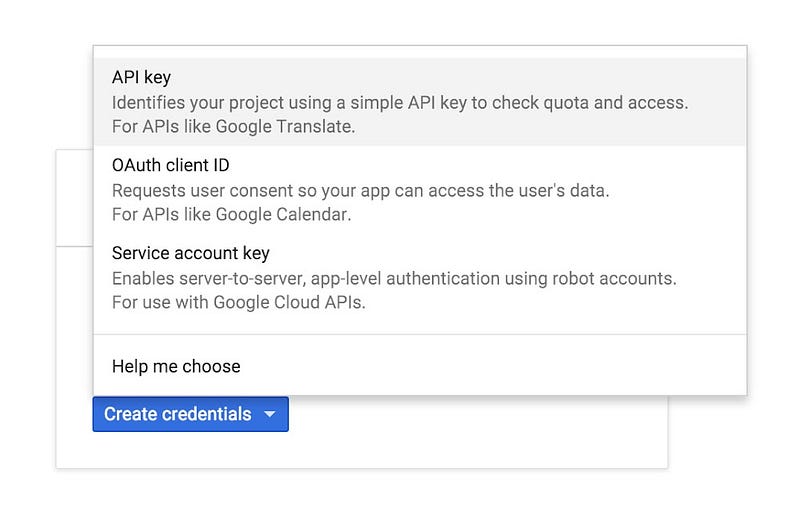
สำหรับ API Key ให้เลือกเป็นแบบ Browser Key เพราะ Cloud Vision API ยังไม่มี Library สำหรับแอนดรอยด์โดยเฉพาะ ที่ใช้ตอนนี้ก็คือยิงผ่าน HTTPS แบบตรงๆกัน
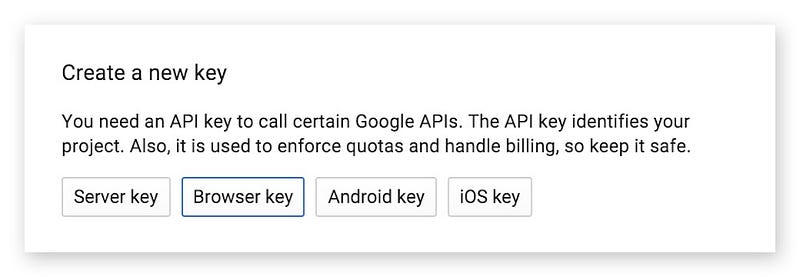
สามารถตั้งชื่อได้ตามใจชอบ แต่ทว่าเจ้าของบล็อกจะเอาไปใช้งานในแอนดรอยด์ จึงไม่จำเป็นต้องกรอกในช่อง URL ของ Website ซึ่งก็มีข้อเสียนะ เพราะการกำหนด URL จะทำให้ API ถูกจำกัดการใช้งานจาก URL ที่กำหนดเท่านั้น เพื่อป้องกันคนอื่นเอา API Key ไปใช้ที่อื่น ซึ่งตอนนี้บนแอนดรอยด์ทำอะไรไม่ได้ก็ต้องยอมปล่อยมันไปก่อน
API Key พร้อมเอาไปใช้งานแล้วจ้า
รูปแบบการใช้งาน Cloud Vision API
เจ้าของบล็อกชอบ Cloud Vision ก็ตรงที่รองรับ REST API ด้วยนี่แหละ สะดวกดี ยิงแบบ POST โดยแนบ API Key เป็น Query ไป ส่วนข้อมูลภาพและ Configuration ในการวิเคราะห์ภาพก็แนบเป็น JSON ตามที่ API กำหนดไว้ลงไปใน Body นั่นเอง
สรุปสั้นๆ
* ใช้ POST Method (เทสด้วย Postman ดูก่อนก็ได้นะ)
* Method ของ Cloud Vision คือ images:annotate
* API Key แนบเป็น Query ชื่อ key
* รูปภาพต้องแปลงให้เป็น Text โดย Encoding เป็นแบบ Base64
* รูปภาพและรูปแบบการวิเคราะห์ส่งเป็น JSON โดยแนบเป็น Body
ทดสอบว่า API Key ใช้งานได้จริงมั้ย
เผื่อผู้ที่หลงเข้ามาอ่านไม่ชัวว่า API Key ที่ขอมาใช้งานได้จริงๆหรือป่าว ให้ลองใช้ Postman ยิงทดสอบดูก็ได้ครับ โดยยิงไปที่ URL ตัวนี้ (เปลี่ยน your_api_key เป็น API Key ของผู้ที่หลงเข้ามาอ่านซะ)
https://vision.googleapis.com/v1/images:annotate?key=your_api_keyซึ่ง Body เจ้าของบล็อกทำเป็น Gist แยกไว้นะครับ เนื่องจากมันยาวมาก Cloud Vision Test with Postman [Gist GitHub] เข้าไปก๊อปจากในนี้มาแปะแทน โดยให้ Body เป็น Raw Text หรือ Raw JSON
กำหนดตามภาพนี้เลย (เจ้าของบล็อกใช้ Postman v2)
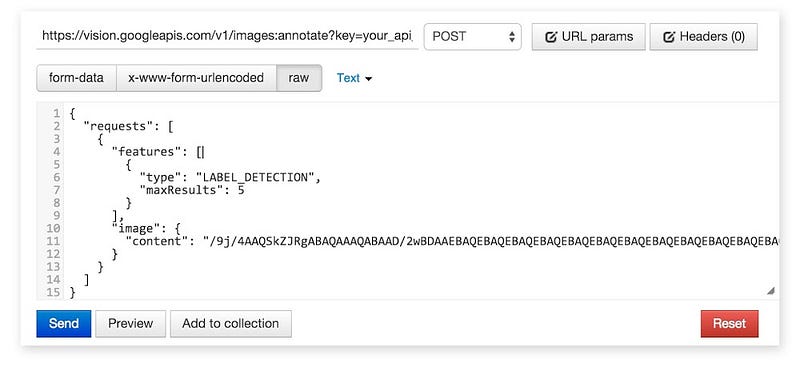
สำหรับค่าที่อยู่ใน content จะยาวมากๆ ไม่ต้องแปลกใจนะครับ เพราะนั่นแหละคือไฟล์ภาพที่แปลงเป็น Text ในรูปของ Base64 ถ้าภาพใหญ่มาก Text ที่แปลงกออกมาก็จะเยอะขึ้นตามนั่นเอง โดยในตัวอย่างที่ให้ไปนี้เป็นแค่ข้อมูลของภาพขนาด 200x200px เท่านั้นเองนะ

เมื่อทดลองยิงด้วย Postman ก็น่าจะได้ผลลัพธ์ประมาณนี้
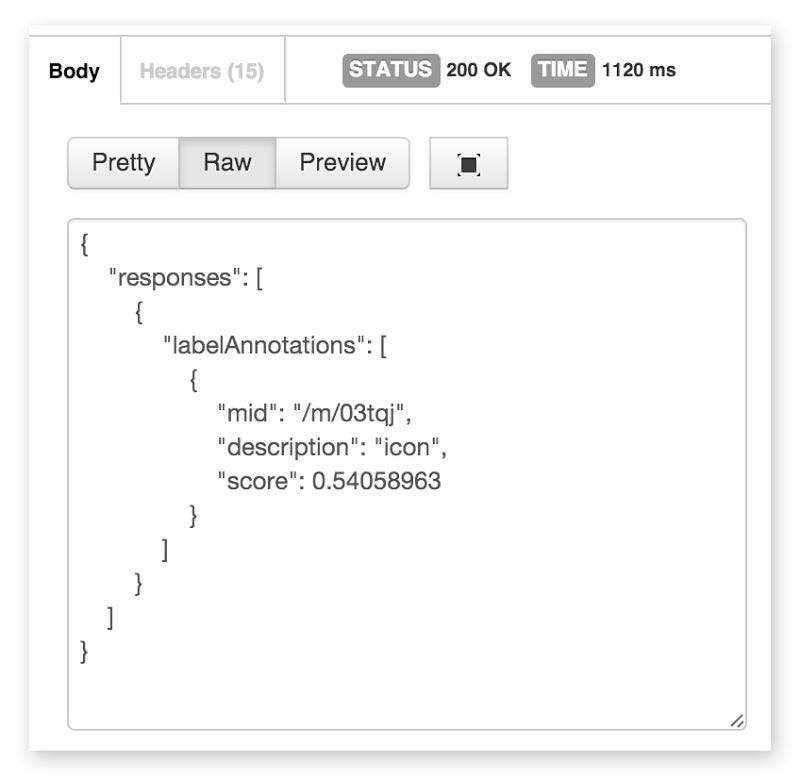
ซึ่ง Cloud Vision วิเคราะห์ออกมาว่าภาพนี้คือ Icon และมีบอกคะแนนการวิเคราะห์ด้วย ซึ่งได้ 0.54058963 (สูงสุดคือ 1)
ถ้าได้เป็น Error ก็ลองเช็คดูใหม่ให้ดีๆนะครับ เมื่อยิงทดสอบได้แล้วก็แปลว่าเอา API Key ไปใช้งานในแอพได้เลย
Configuration สำหรับการ Request
ถ้าดูจากตัวอย่างที่ให้ทดสอบในตอนแรก จะเห็นว่าใน JSON มีการกำหนด Type ของ Feature ด้วย อันนั้นแหละที่เจ้าของบล็อกเรียกว่า Configuration ซึ่งตรงนี้จะสามารถกำหนดการวิเคราะห์ของ API ได้ ว่าจะให้วิเคราะห์หาอะไรจากในภาพ จากตัวอย่างก็คือให้วิเคราะห์ว่าภาพดังกล่าวคือภาพอะไร โดยผลลัพธ์ที่ได้มีโอกาสมากกว่า 1 ดังนั้นเจ้าของบล็อกจึงกำหนดไว้ว่าเอาผลลัพธ์แค่ 5 อันแรกสุดเท่านั้น ซึ่งจะเรียงตามคะแนน ซึ่งคะแนนคือความแม่นยำของคำตอบ (เหมือนผู้ที่หลงเข้ามาอ่านบอกว่า “รูปนี้คือเจ้าของบล็อก 100%” นั่นเอง) และเนื่องจากความเป็นไปได้ของภาพมีแค่ Icon เท่านั้น จึงทำให้ API ส่งผลลัพธ์มาแค่อย่างเดียว
ซึ่งสามารถดูรายละเอียดของ Configuration ได้ที่ Method images.annotate [Google Cloud Platform] (อยู่ในส่วนของ Request Body) ซึ่งสรุปทั้งหมดออกมาเป็นแบบนี้
{ "requests": [ { "features": [ { "type": "type_of_image_feature", "maxResults": number_of_maximum_result }, ... ], "image": { "content": "image_in_base64_encoding", "source": { "gcsImageUri": "gs://bucket_name/object_name" } }, "imageContext": { "latLongRect": { "minLatLng": { "latitude": latitude_in_degrees, "longitude": longitude_in_degrees }, "maxLatLng": { "latitude": latitude_in_degrees, "longitude": longitude_in_degrees } }, "languageHints": [ "en", "th", ... ] } } ] }Configuration จะประกอบไปด้วย 3 ส่วนคือ Feature, Image และ Image Context ซึ่งในการ Request แต่ละครั้งจะต้องกำหนด Feature และ Image เป็นอย่างน้อย เพื่อส่งข้อมูลภาพและระบุว่าต้องการให้วิเคราะห์แบบไหน (รูปแบบ Configuration ที่น้อยที่สุดก็ตามตัวอย่างที่ให้ทดสอบในตอนแรกนั่นแหละ)
เดี๋ยวจะขออธิบายทีละส่วนนะ เริ่มจาก Image ก่อน
Image
{ "image": { "content": "image_in_base64_encoding", "source": { "gcsImageUri": "gs://bucket_name/object_name" } } }สำหรับรูปภาพที่ต้องการส่งให้ Cloud Vision กำหนดได้ 2 แบบคือ Content กับ Source
โดยที่ Content คือข้อมูลรูปภาพแบบ Base64 สำหรับกรณีที่ส่งภาพจากเครื่องโดยตรงนั่นเอง ส่วน Source คือกำหนด Path ของภาพที่อยู่ใน Google Cloud Storage
ให้กำหนดแค่อย่างใดอย่างหนึ่งก็พอ แต่ถ้ากำหนดทั้ง 2 อย่างพร้อมๆกัน ตัว Cloud Vision จะอิงจาก Content เป็นหลัก
Feature
{ "features": [ { "type": "type_of_image_feature", "maxResults": number_of_maximum_result }, ... ] }สำหรับ Feature สามารถกำหนดได้มากกว่า 1 Feature (ไม่สิ ต้องบอกว่าอย่างน้อย 1 Feature เนอะ) โดยข้างในจะเป็นการกำหนด Type และ Max Result
ซึ่ง Type หรือรูปแบบในการวิเคราะห์จะมีทั้งหมดดังนี้
* TYPE_UNSPECIFIED ไม่กำหนดรูปแบบในการค้นหา
* FACE_DETECTION ค้นหาใบหน้าของคนที่อยู่ในภาพ
* LANDMARK_DETECTION ค้นหาสถานที่สำคัญที่อยู่ในภาพ
* LOGO_DETECTION ค้นหาโลโก้ที่อยู่ในภาพ
* LABEL_DETECTION ค้นหาประเภทของเนื้อหาในภาพ
* TEXT_DETECTION ค้นหาข้อความที่อยู่ในภาพ
* SAFE_SEARCH_DETECTION ค้นหาว่าภาพมีเนื้อหาที่เหมาะสมปลอดภัยหรือไม่
* IMAGE_PROPERTIES ค้นหาชุดสีที่อยู่ในภาพ
ส่วน Max Results ก็ให้กำหนดเป็นตัวเลขลงไปเลย ว่าจะให้แสดงผลลัพธ์มากสุดเท่าไร (อิงจากคะแนนสูงสุด)
Image Context
{ "imageContext": { "latLongRect": { "minLatLng": { "latitude": latitude_in_degrees, "longitude": longitude_in_degrees }, "maxLatLng": { "latitude": latitude_in_degrees, "longitude": longitude_in_degrees } }, "languageHints": [ "en", "th", ... ] } }เป็นการกำหนดข้อมูลคร่าวๆเพื่อช่วยให้ Cloud Vision วิเคราะห์ได้ง่ายขึ้น ซึ่งจะมีอยู่ 2 อย่างด้วยกันคือ Lat/Lng Rectangle และ Language Hints
Lat/Lng Rectangle เป็นการกำหนดขอบเขตของภาพนั้นๆว่าอยู่บริเวณไหนของโลก โดยจะมีการกำหนดเป็น Lat/Lng โดยแบ่งเป็น Max และ Min ด้วย เหมาะสำหรับใช้กับ Landmark Detection
Language Hints เป็นการบอก Cloud Vision ในภาพนั้นเป็นภาษาอะไร เพื่อช่วยให้วิเคราะห์ Text Detection ได้ง่ายขึ้น โดยกำหนดหลายๆภาษาได้พร้อมกัน ส่วนวิธีกำหนดให้ดูจากที่นี่ Language reference [Google Cloud Platform]
Response ที่ได้จาก Cloud Vision API
{ "responses": [ { "landmarkAnnotations": [ { "mid": "map_id", "description": "name_of_landmark", "score": score, "boundingPoly": { "vertices": [ { "x": x_position, "y": y_position }, ... ] }, "locations": [ { "latLng": { "latitude": latitude_of_location, "longitude": longitude_of_location } } ] }, ... ], "labelAnnotations": [ { "mid": "map_id", "description": "name_of_label", "score": score }, ... ], "logoAnnotations": [ { "mid": "map_id", "description": "name_of_logo", "score": score, "boundingPoly": { "vertices": [ { "x": x_position, "y": y_position }, ... ] } }, ... ], "faceAnnotations": [ { "boundingPoly": { "vertices": [ { "x": x_position, "y": y_position }, ... ] }, "fdBoundingPoly": { "vertices": [ { "x": x_position, "y": y_position }, ... ] }, "landmarks": [ { "type": "type_of_face_landmark", "position": { "x": x_position, "y": y_position, "z": z_position } }, ... ], "rollAngle": roll_angle, "panAngle": yaw_angle, "tiltAngle": pitch_angle, "detectionConfidence": detection_confidence, "landmarkingConfidence": face_landmarking_confidence, "joyLikelihood": "likelihood_result", "sorrowLikelihood": "likelihood_result", "angerLikelihood": "likelihood_result", "surpriseLikelihood": "likelihood_result", "underExposedLikelihood": "likelihood_result", "blurredLikelihood": "likelihood_result", "headwearLikelihood": "likelihood_result", }, ... ], "textAnnotations": [ { "locale": "locale_of_language", "description": "text_in_the_image", "boundingPoly": { "vertices": [ { "x": x_position, "y": y_position }, ... ] } }, ... ], "safeSearchAnnotation": { "adult": "likelihood_result", "spoof": "likelihood_result", "medical": "likelihood_result", "violence": "likelihood_result" }, "imagePropertiesAnnotation": { "dominantColors": { "colors": [ { "color": { "red": red_value, "green": green_value, "blue": blue_value }, "score": score, "pixelFraction": fraction }, ... ] } }, "error": { "code": result_code_of_error, "message" : "error_message" } } ] }{ "landmarkAnnotations": [ { "mid": "map_id", "description": "name_of_landmark", "score": score, "boundingPoly": { "vertices": [ { "x": x_position, "y": y_position }, ... ] }, "locations": [ { "latLng": { "latitude": latitude_of_location, "longitude": longitude_of_location } } ] } ] }เป็น Response จาก Landmark Detection ที่จะบอกชื่อสถานที่สำคัญ (มีได้มากกว่า 1 สถานที่) มีการบอกพื้นที่ในภาพด้วยว่าตรงไหนที่ Detect เป็น Landmark ซึ่งจะบอกเป็นแบบ Bounding Poly และนอกจากนี้มีการบอกด้วยว่าสถานที่สำคัญที่ว่านั้นอยู่พิกัดไหนบนโลก (มีได้มากกว่า 1 ตำแหน่ง)
Label Annotations
{ "labelAnnotations": [ { "mid": "map_id", "description": "name_of_label", "score": score }, ... ] }ตัวนี้ไม่ค่อยซับซ้อนมากนัก เป็น Response จาก Label Detection ซึ่งจะบอกว่าเนื้อหาในภาพเป็นอะไร เช่น หุ่นยนต์, ตัวตลก, รถยนต์ หรือผลไม้ เป็นต้น
Logo Annotations
{ "logoAnnotations": [ { "mid": "map_id", "description": "name_of_logo", "score": score, "boundingPoly": { "vertices": [ { "x": x_position, "y": y_position }, ... ] } }, ... ] }เป็น Response ที่ได้มาจาก Logo Detection โดยจะบอกว่าโลโก้ในภาพนั้นเป็นโลโก้อะไร มีการบอกตำแหน่งบนภาพด้วยว่าเป็นบริเวณไหน
Face Annotations
{ "faceAnnotations": [ { "boundingPoly": { "vertices": [ { "x": x_position, "y": y_position }, ... ] }, "fdBoundingPoly": { "vertices": [ { "x": x_position, "y": y_position }, ... ] }, "landmarks": [ { "type": "type_of_face_landmark", "position": { "x": x_position, "y": y_position, "z": z_position } }, ... ], "rollAngle": roll_angle, "panAngle": yaw_angle, "tiltAngle": pitch_angle, "detectionConfidence": detection_confidence, "landmarkingConfidence": face_landmarking_confidence, "joyLikelihood": "likelihood_result", "sorrowLikelihood": "likelihood_result", "angerLikelihood": "likelihood_result", "surpriseLikelihood": "likelihood_result", "underExposedLikelihood": "likelihood_result", "blurredLikelihood": "likelihood_result", "headwearLikelihood": "likelihood_result", }, ... ] }ข้อมูลจาก Face Detection จะค่อนข้างเยอะหน่อย เพราะว่าในนี้บอกข้อมูลต่างๆจาก Face Detection แทบครบ สามารถค้นหาได้มากกว่า 1 คน มีการบอกพื้นที่บนภาพที่ตรวจจับใบหน้าได้ (Bounding Poly) และบริเวณที่วิเคราะห์ใบหน้า (Face Detection Boulding Poly)
ที่อึ้งยิ่งกว่าคือมีการบอกว่าอวัยวะบนใบหน้าอยู่ตำแหน่งไหนบ้างของภาพ บอกมาเป็น XYZ เลยนะเออ (บอกความลึกได้ด้วย!!) โดยอวัยวะที่ว่าจะมีทั้งหมดดังนี้
* LEFT_EYE
* RIGHT_EYE
* LEFT_OF_LEFT_EYEBROW
* RIGHT_OF_LEFT_EYEBROW
* LEFT_OF_RIGHT_EYEBROW
* RIGHT_OF_RIGHT_EYEBROW
* MIDPOINT_BETWEEN_EYES
* NOSE_TIP
* UPPER_LIP
* LOWER_LIP
* MOUTH_LEFT
* MOUTH_RIGHT
* MOUTH_CENTER
* NOSE_BOTTOM_RIGHT
* NOSE_BOTTOM_LEFT
* NOSE_BOTTOM_CENTER
* LEFT_EYE_TOP_BOUNDARY
* LEFT_EYE_RIGHT_CORNER
* LEFT_EYE_BOTTOM_BOUNDARY
* LEFT_EYE_LEFT_CORNER
* RIGHT_EYE_TOP_BOUNDARY
* RIGHT_EYE_RIGHT_CORNER
* RIGHT_EYE_BOTTOM_BOUNDARY
* RIGHT_EYE_LEFT_CORNER
* LEFT_EYEBROW_UPPER_MIDPOINT
* RIGHT_EYEBROW_UPPER_MIDPOINT
* LEFT_EAR_TRAGION
* RIGHT_EAR_TRAGION
* LEFT_EYE_PUPIL
* RIGHT_EYE_PUPIL
* FOREHEAD_GLABELLA
* CHIN_GNATHION
* CHIN_LEFT_GONION
* CHIN_RIGHT_GONION
ครอบจักรวาลชิบหาย… ซึ่งอวัยวะแต่ละส่วนก็จะบอกเป็น XYZ เช่นกัน แต่ถ้าส่วนไหนหาไม่เจอก็จะไม่แสดงใน Response
มีการบอกด้วยว่าบุคคลในภาพนั้นแหงนหน้าหรือหันหน้ามากน้อยแค่ไหน โดยบอกค่าเป็น Roll, Yaw และ Pitch ส่วนความแม่นยำในการตรวจจับใบหน้าจะไม่ได้บอกมาเป็นคะแนน แต่จะบอกเป็นค่า Detection confidence กับ Face landmarking confidence แทน
และยังสามารถบอกอารมณ์ของใบหน้าและความชัดของใบหน้าอีกด้วย (ชักจะเวอร์เกินไปละ) สำหรับอารมณ์ที่สามารถวิเคราะห์ออกมาได้จะมี
ซึ่งอารมณ์บนใบหน้าพวกนี้จะไม่ได้วิเคราะห์ออกมาเป็นตัวเลข 0 ถึง 1 แต่ว่าจะบอกเป็นรูปแบบข้อความดังนี้แทน
นอกจากนี้ยังบอกได้อีกว่าภาพนั้นๆแสงน้อยไปหรือป่าว? เบลอไปมั้ย? หรือบุคคลในภาพสวมใส่อะไรอยู่บนหัวหรือไม่ (….)
Text Annotations
{ "textAnnotations": [ { "locale": "locale_of_language", "description": "text_in_the_image", "boundingPoly": { "vertices": [ { "x": x_position, "y": y_position }, ... ] } }, ... ] }เป็น Response จาก Text Detection ที่จะบอกว่าข้อความที่อยู่ในภาพเป็นคำว่าอะไร มีการบอกด้วยว่าเป็นภาษาอะไร และตำแหน่งของข้อความอยู่ตรงไหนของภาพ
Safe Search Annotations
{ "safeSearchAnnotation": { "adult": "likelihood_result", "spoof": "likelihood_result", "medical": "likelihood_result", "violence": "likelihood_result" } }อันนี้เป็น Response จาก Safe Search Detection ที่จะบอกว่าเนื้อหาในภาพเหมาะสำหรับเด็กมั้ย เป็นภาพเกินจริงมั้ย เกี่ยวกับยาหรือป่าว และมีความรุนแรงหรือไม่ ซึ่งจะแสดงผลลัพธ์ตามที่วิเคราะห์ได้ดังนี้
Image Properties Annotations
{ "imagePropertiesAnnotation": { "dominantColors": { "colors": [ { "color": { "red": red_value, "green": green_value, "blue": blue_value }, "score": score, "pixelFraction": fraction }, ... ] } } }คุณสมบัติเกี่ยวกับสีบนภาพนั้นๆ โดยจะแสดงข้อมูลเกี่ยวกับค่าสี RGB
Error
{ "error": { "code": result_code_of_error, "message": "error_message" } }ในกรณีที่มีปัญหาเกิดขึ้นในขณะเรียกใช้งาน Cloud Vision ก็จะมี Response ที่เป็น Error กลับมาให้พร้อม Result Code และ Message เพื่อให้สามารถตรวจสอบได้
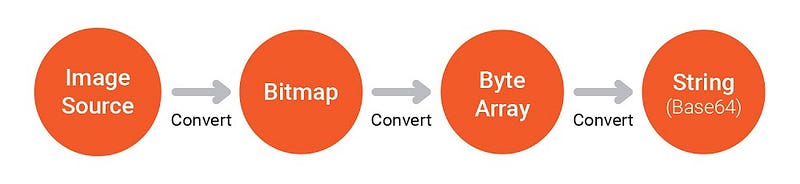
แปลง Bitmap ให้กลายเป็น Byte Array
public static byte[] convertBitmapToByteArray(Bitmap bitmap) { ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream(); bitmap.compress(Bitmap.CompressFormat.JPEG, 100, byteArrayOutputStream); //bm is the bitmap object return byteArrayOutputStream.toByteArray(); }public static String convertByteArrayToBase64String(byte[] data) { return Base64.encodeToString(data, Base64.DEFAULT); }